This page provides an in-depth look at how Cloudflare harnesses physical chaos to bolster Internet security and explores the potential of public randomness and timelock encryption in applications.
There is the story of Cloudflare’s LavaRand, a system that uses physical entropy sources like lava lamps for Internet security, has grown over four years, diversifying beyond its original single source. Cloudflare handles millions of HTTP requests secured by TLS, which requires secure randomness. LavaRand contributes true randomness to Cloudflare’s servers, enhancing the security of cryptographic protocols.
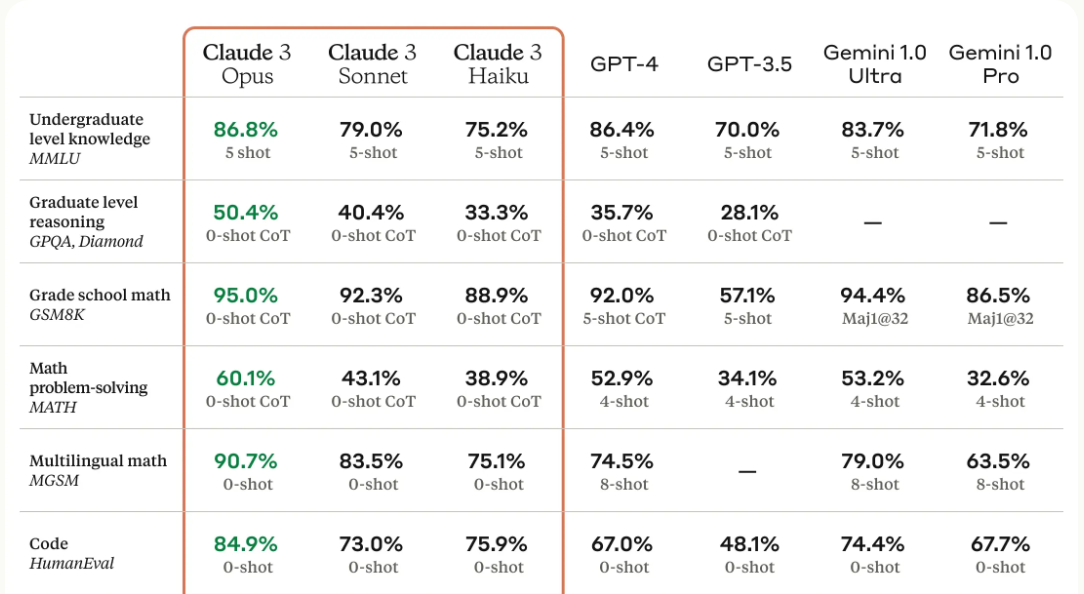
Introducing three new AI models – Haiku, Sonnet, and Opus – with ascending capabilities for various applications1. Opus and Sonnet are now accessible via claude.ai and the Claude API, with Haiku coming soon. Opus excels in benchmarks for AI systems.
All models feature improved analysis, forecasting, content creation, code generation, and multilingual conversation abilities.
kubectl trick of the week.
.bahsrc
function k_get_images_digests {
ENV="$1";
APP="$2"
kubectl --context ${ENV}-aks \
-n ${ENV}-security get pod \
-l app.kubernetes.io/instance=${APP} \
-o json| jq -r '.items[].status.containerStatuses[].imageID' |uniq -c
}
alias k-get-images-id=k_get_images_digests
Through this alias you can get all the image digests of a specific release filtering by its label and then filter for unique values
I know this is a very opinionated topic and "agile coaches" everywhere are ready to fight, so I'll try to keep it short making clear this is based just on my experience and on discussions with other engineers and managers in different companies and levels.
We’re a team of Scaled Agile SRE, Working together to deliver quality, Breaking down silos and communication gaps, We’re on a mission to make sure nothing lacks.
We follow the SAFe framework to a tee, With its ARTs and PI planning, we’re not so free, To deliver value in every sprint, Continuous delivery is our mint.
Chorus: Scaled Agile and SRE, Together we achieve, Quality and speed, We’re the dream team.
We prioritize work and plan ahead, Collaborate and ensure nothing’s left unsaid, We monitor, measure, and analyze, Our systems to avoid any surprise.
Chorus
We take ownership and accountability, To deliver value with reliability.
Chorus
So when you need to deliver at scale, You know who to call and who won’t fail, Scaled Agile SRE, Together we’re the ultimate recipe.
ChatGPT4 & me
To not make this post too verbose I’ll try to focus only on two points that I find paramount in a SRE team living in a Scaled Agile framework (SAFe) with a Kanban style approach: capacity planning and value flow.
Capacity
What is your definition of capacity?
Most of the teams don’t ask this simple question to themselves and then struggle for months to give a better planning. Is that the sum of our hours per day? Or is it calculated based on each one capacity after removing the average amount of support, maintenance, security fixes and operations emergencies?
While learning to drive, in general but even more for a motorcycle, you’re introduced to the paradoxical concept of “expect the unexpected!“
Of course, this won’t save always your life but surely it can reduce a lot the probability of you having an accident. It will because you’ll stick to some best practices tested in tens of years of driving. Like to not surpass while not seeing the exit of a turn, don’t drive too close to the previous vehicle, always consider the status of the road, the surroundings and your tires before speeding up…
The good part of computer science is that you have a lot of incidents!
But this becomes a value only if you start measuring them and then learning from them.
So we should consider our work less like artistic craftsmanship and more from a statistical point of view, going back over the closed user stories and trying to get some average completion time splitting by categories (support, emergencies, toil elimination, research…)
Nobody complains!
You have now a rough estimation of how much time is spent on variable actions and maintenance, let’s say 20 hours per week.
You know also your fixed appointments will be at least 20 min per day for the daily meeting, 1 hour per week to share issues coming from development teams and 1 hour for infrastructure refinement (open tasks evaluation, innovations to adopt or to share with the team…).
Let’s say you won’t be neither on support (answering dev teams questions and providing them new resources) nor on call (supporting operations team solving emergencies).
This will give you around 40 – 20 – 1 (dailies) – 1 (weekly) – 1 (infra) – 1 (dev team weekly) – 0.5 (weekly with your manager) = 15.5 h/w of capacity, meaning 31h of capacity for the next iteration if it lasts two weeks.
Probably less since you know you have already other two periodical useless meeting of one hour each, so let’s round to 13 h/w ≈ 150 min/day of “uninterrupted” work.
Well… actually to not get crazy and start physically fighting my hardware I need a couple of breaks, let’s say 15 min in the morning and the same in the middle of the afternoon.
That means ≈ 120 min/day of “uninterrupted” work.
Fine, I assume I can take that user story we’ve evaluated 10h with high priority for the next week and a smaller one for the next week leaving some contingency space.
We publish this results in the PI planning and to the management, and nobody complains.
Long story short: if nobody ever complains probably you’re not involving stakeholders correctly in your PI Planning or worse you’re not involving them at all!
And that’s bad.
Why are you working on those features?
Why those features exist in first place?
If your team is decoupled from the business view, are you sure that all this effort will help something? Or do you smell re-work and failure?
We should mention also that these planning didn’t leave any space for research and creative thinking. People will start solving issues quick and dirty more and more.
Yeah, I could call Moss and Roy for a good pair programming sessions since they have already solved this issue in the last iteration but… who wants another meeting? Let’s copy paste this work around and go on for now…
How much value has my work?
To measure value, we need some kind of indicator.
There are a lot of articles on cons and pros about setting metrics for our goal even before starting. Let’s say here that you want to have a few custom indicators that proves to be a good estimation based on previous experience, they should take in consideration side effects and they should be some kind of aggregated result meaning that they shouldn’t be easily hackable (working only to improve the metrics and not the quality).
Maybe we introduce general service availability and average service response time as two service level indicators (SLI).
Then we start having management working on Value Stream Analysis to understand where this values since it was requested as a new feature by the customers before the current agile train.
They succeed to reduce periodical meetings by 50% and increase 1 to 1 communication. Now dev teams are able to solve issues by themselves thanks to better documentation and run-books etc…
Conclusions
Imagine you are trying to implement a complex application in Golang, after a while you’re still failing, so you decide to switch to Java Quarkus, that you don’t know and to mess around because you heard it is easier. After a while guess what? It still doesn’t work.
The same is for the Agile frameworks. People expect them to solve stuff auto-magically, but if we don’t put effort into changing our own behavior, into measuring our-self in order to improve (and not to give our manager micromanagement power), using the latest agile methodology will never solve our Friday afternoon issues.
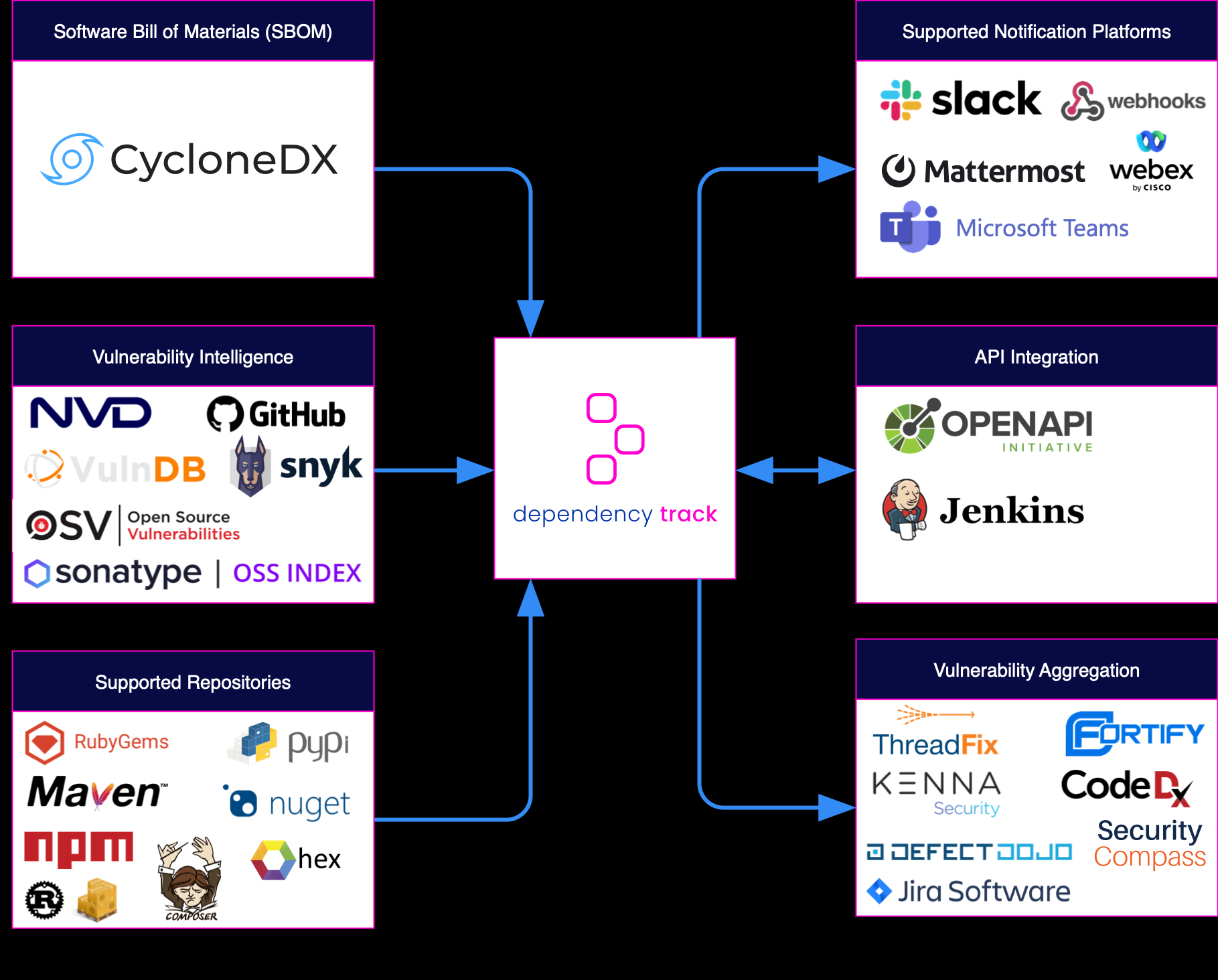
After the deep theoretical dive of the previous article let’s try to translate all that jazz in some real example and practical use cases for implementing a continuous SBOM file generation.
Verse 1) Grype and Syft, two brothers, so true In the world of tech, they’re both making their due One’s all about security, keeping us safe The other’s about privacy, a noble crusade
(Chorus) Together they stand, with a mission in hand To make the digital world a better place, you understand Grype and Syft, two brothers, so bright Working side by side, to make the world’s tech just right
(Verse 2) Grype’s the strong one, he’s got all the might He’ll protect your data, day and night Syft’s got the brains, he’s always so smart He’ll keep your secrets, close to your heart
(Chorus)
ChatGPT
[Azure pipelines] Grype + Syft
Following there is a working example of a sample Azure pipeline comprehending two templates for having a vulnerabilities scanner job and a parallel SBOM generation.
The first job will leverage Grype, a known open-source project by Anchore, while for the second one we will use its brother/sister Syft.
At the beginning what we do is to make sure this become a continuous scanning by selecting pushes on master as a trigger action, for example to have it start after each merge on a completed pull request.
You can specify the full name of the branch (for example, master) or a wildcard (for example, releases/*). See Wildcards for information on the wildcard syntax. For more complex triggers that use exclude or batch, check the full syntax on Microsoft documentation.
In the Grype template we will
download the latest binary from the public project
set the needed permissions to read and execute the binary
check if there is a grype.yaml with some extra configurations
run the vulnerability scanner on the given image. The Grype databse will be updated before each scan
save the results in a file “output_grype”
use the output_grype to check if there are alerts that are at least High, if so we want also a Warning to be raised in our Azure DevOps web interface.
In the Syft template we will have a similar list of parameter, with the addition of the SBOM file format (json, text, cyclonedx-xml, cyclonedx-json, and much more).
After scanning our image for all its components we then publish the artifact in our pipeline, since probably we’ll want to pull this list from a SBOM analysis tool (i.e: OWASP Dependency-Track, see previous article).
In GitHub it would be even easier since Syft is offered as a service by an Anchore action.
By default, this action will execute a Syft scan in the workspace directory and upload a workflow artifact SBOM in SPDX format. It will also detect if being run during a GitHub release and upload the SBOM as a release asset.
Example of Software Life Cycle and Bill of Materials Assembly Line
DevOps companies have always been in a constant pursuit of making their software development process faster, efficient, and secure. In the quest for better software security, a shift is happening from using traditional vulnerability scanners to utilizing Software Bill of Materials (SBOM) generation. This article explains why devops companies are making the switch and how SBOM generation provides better security for their software.
A CVE is known to all, it’s a security flaw call It’s a number assigned, to an exposure we’ve spied It helps track and prevent, any cyber threats that might hide!
Vulnerability scanners are software tools that identify security flaws and vulnerabilities in the code, systems, and applications. They have been used for many years to secure software and have proven to be effective. However, the increasing complexity of software systems, the speed of software development, and the need for real-time security data have exposed the limitations of traditional vulnerability scanners.
Executive Order 14028
Executive Order 14028, signed by President Biden on January 26, 2021, aims to improve the cybersecurity of federal networks and critical infrastructure by strengthening software supply chain security. The order requires federal agencies to adopt measures to ensure the security of software throughout its entire lifecycle, from development to deployment and maintenance.
NIST consulted with the National Security Agency (NSA), Office of Management and Budget (OMB), Cybersecurity & Infrastructure Security Agency (CISA), and the Director of National Intelligence (DNI) and then defined “critical software” by June 26, 2021.
Such guidance shall include standards, procedures, or criteria regarding providing a purchaser a Software Bill of Materials (SBOM) for each product directly or by publishing it on a public website.
Object Model
SBOM Object Model
SBOM generation is a newer approach to software security that provides a comprehensive view of the components and dependencies that make up a software system. SBOMs allow devops companies to see the full picture of their software and understand all the components, including open-source libraries and dependencies, that are used in their software development process. This information is critical for devops companies to have, as it allows them to stay on top of security vulnerabilities and take the necessary measures to keep their software secure.
The main advantage of SBOM generation over vulnerability scanners is that SBOMs provide a real-time view of software components and dependencies, while vulnerability scanners only provide information about known vulnerabilities.
One practical example of a SBOM generation tool is Trivy, an open-source vulnerability scanner for container images and runtime environments. It detects vulnerabilities in real-time and integrates with the CI/CD pipeline, making it an effective tool for devops companies.
Another example is Anchore Grype, a cloud-based SBOM generation tool that provides real-time visibility into software components and dependencies, making it easier for devops companies to stay on top of security vulnerabilities.
OWASP Dependency-Track integrations
Finally, Dependency Track is another great tool by OWASP that allows organizations to identify and reduce risk in the software supply chain. The Open Web Application Security Project® (OWASP) is a nonprofit foundation that works to improve the security of software through community-led open-source software projects.
The main features of Dependency Track include:
Continuous component tracking: Dependency Track tracks changes to software components and dependencies in real-time, ensuring up-to-date security information.
Vulnerability Management: The tool integrates with leading vulnerability databases, including the National Vulnerability Database (NVD), to provide accurate and up-to-date information on known vulnerabilities.
Policy enforcement: Dependency Track enables organizations to create custom policies to enforce specific security requirements and automate the enforcement of these policies.
Component Intelligence: The tool provides detailed information on components and dependencies, including licenses, licenses and age, and other relevant information.
Integration with DevOps tools: Dependency Track integrates with popular DevOps tools, such as Jenkins and GitHub, to provide a seamless experience for devops teams.
Reporting and Dashboards: Dependency Track provides customizable reports and dashboards to help organizations visualize their software components and dependencies, and identify potential security risks.
So, your manager just finished a SCRUM course, because your enterprise company thinks it is the cutting-edge management process and now everything should be SCRUM or something very close…
Are you doing SCRUM?
How much time do you dedicate to sprint planning?
Do you have a fixed, cross-functional and autonomous team assigned to fixed length sprints full time?
Do you have a dedicated person for managing business requirements inside a backlog?
Are you taking short (5 min per person) daily stand-up meetings where everyone shares just the blocking points to the rest of the team and the Scrum master?
Are you sure you need Scrum?
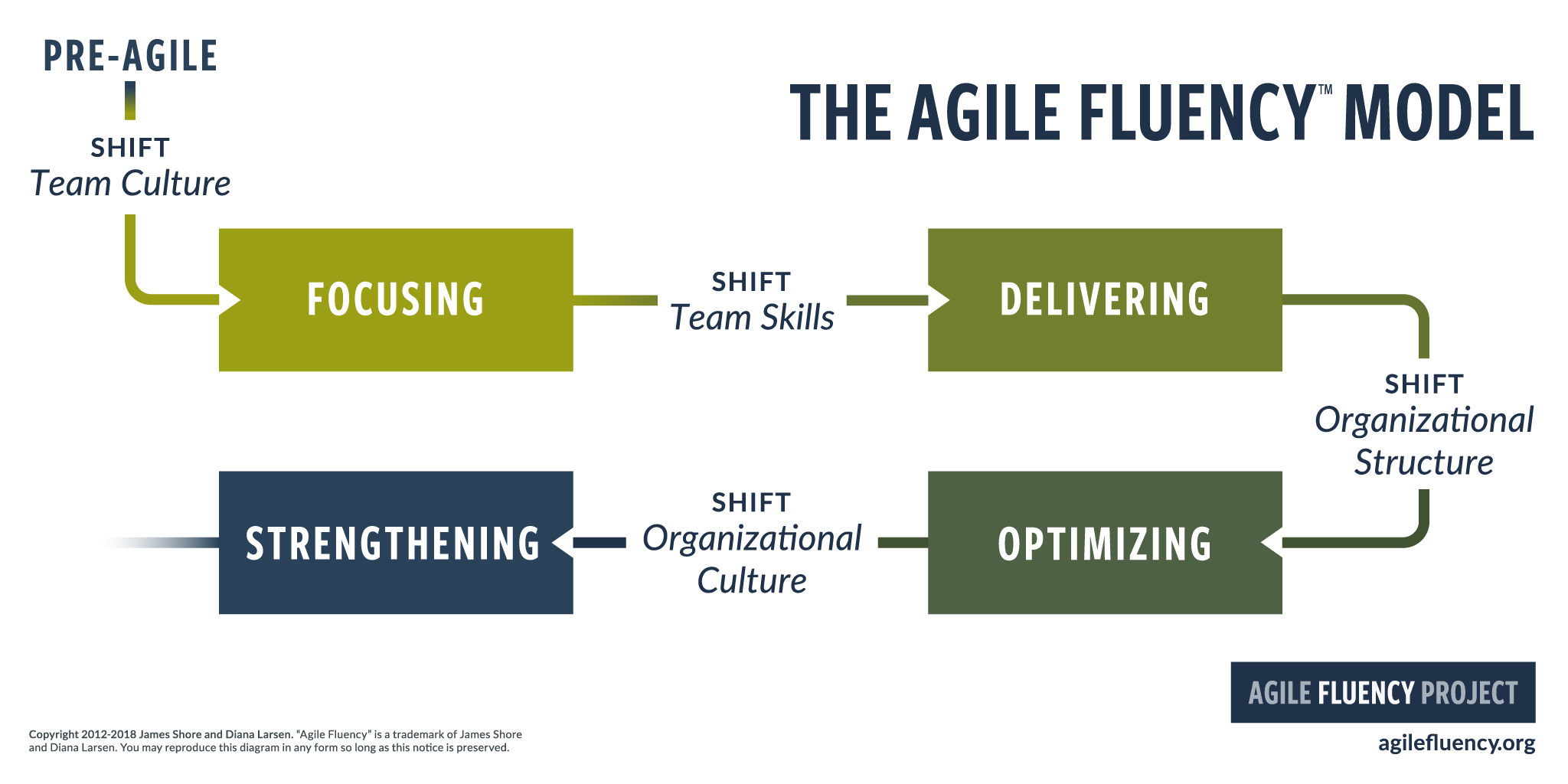
Applying a complex methodology when you are in a deep technical depth situation will just make the things worse. It is what Martin Fowler calls Flaccid Scrum.
In this case what you really need to do first is to increment your delivery fluency starting from practices like Continuous Delivery or applying pragmatic methodologies like Extreme Programming.
For many people, this situation is exacerbated by Scrum because Scrum is a process that’s centered on project management techniques and deliberately omits any technical practices, in contrast to (for example) Extreme Programming.
Martin Fowler
Fluent Delivering teams not only focus on business value, they realize that value by shipping as often as their market will accept it. This is called “shipping on the market’s cadence.”
Delivering teams are distinguished from Focusing teams not only by their ability to ship, but their ability to ship at will.
Extreme Programming (XP) pioneered many of the techniques used by delivering teams and it remains a major influence today. Nearly all fluent teams use its major innovations, such as continuous integration, test-driven development, and “merciless” refactoring.
In recent years, the DevOps movement has extended XP’s ideas to modern cloud-based environments.
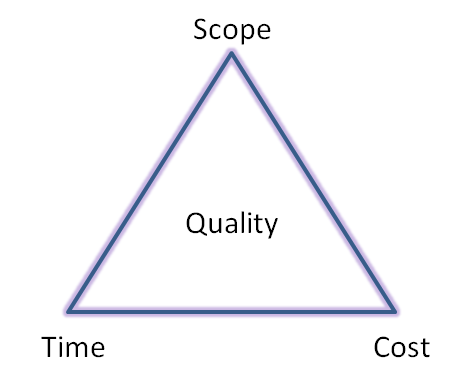
Triple constraint triangle
Comparing Scrum with Lean
So, let’s say your company’s managers already read this article and its related sources, so you’re really going fast on your CI/C processes and almost everything is versioned and monitored…
How to manage that in a big company with a lot of distributed teams?
Let’s give a fast look to Lean and then to Disciplined Agile Delivery.
SCHEDULE/ TIME
Agile: fixed timeboxes and release plans are used to schedule your next activities. You need to sort your activities in order to plan your tasks by priority in a managed backlog.
Lean: the schedule can vary based on priority of the tasks exposed in a Kanban board that should be always visible by every one. No need for all the team to be full time on one task, the experts can use a divide-and-conquer approach, focusing on the most critical parts first and releasing when it is possible, following the customer Service Agreements.
SCOPE
Agile: the sprint backlog will contain the minimum scope necessary to develop the next product release
Lean: the tasks are generated by customer tickets where they specify also the urgency level.
BUDGET
Agile: ROI and Burndown charts are used to monitor budget during the project
Lean: KPI and Service Level Agreement are used to continuously check product quality and the production chain efficiency
Disciplined Agile Delivery
The Disciplined Agile Delivery (DAD) process framework is a peoplefirst, learning-oriented hybrid agile approach to IT solution delivery. It has a risk-value lifecycle, is goal-driven, is scalable, and is enterprise aware.
Here the differences from Scrum, Lean and Disciplined Agile Delivery.
PEOPLE
Keep the docs at the really minimum. The traditional approach of having formal handoffs of work products (primarily documents) between different disciplines such as requirements, analysis, design, test, and development is a very poor way to transfer knowledge that creates bottlenecks and proves in practice to be a huge source of waste of both time and money.
Teams should be cross-functional with no internal hierarchy. In Scrum for instance, there are only three Scrum team roles: Scrum Master, product owner, and team member. The primary roles described by DAD are stakeholder, team lead, team member, product owner, and architecture owner.
LEARNING
The first aspect is domain learning: how are you exploring and identifying what your stakeholders need, and perhaps more importantly, how are you helping the team to do so?
The second aspect is process learning, which focuses on learning to improve your process at the individual, team, and enterprise levels.
The third aspect is technical learning, which focuses on understanding how to effectively work with the tools and technologies being used to craft the solution for your stakeholders.
What may not be so obvious is the move away from promoting specialization among your staff and instead fostering a move toward people with more robust skills, something called being a generalizing specialist. Progressive organizations aggressively promote learning opportunities for their people outside their specific areas of specialty as well as opportunities to actually apply these new skills.
HYBRID PROCESS
DAD will take elements from the other methodologies to tailor a process that best suites an enterprise agile team:
prioritized backlog from Scrum
Kanban dashboard and limit work in progress approach from Kanban (Toyota production system)
Agile way to manage data a and documents
CI/CD, TDD, collective ownership practices from Extreme Programming and DevOps
IT SOLUTIONS OVER SOFTWARE
As IT professionals we do far more than just develop software. Yes, software is clearly important, but in addressing the needs of our stakeholders we often provide new or upgraded hardware, change the business/operational processes that stakeholders follow, and even help change the organizational structure in which our stakeholders work.
Agile was created mostly by developers and consultants, we need to focus more on business needs and company processes optimizations.
Goal-Driven Delivery Lifecycle
It is a delivery process extending the Scrum one, starting from the initial vision to the release in production;
explicit phases: Inception, Construction and Transition;
Inception: initiate team, schedule stakeholders meetings, requirements collection, architecture design, align with company policies, release planning, set up environment
Transition: delivering in production. This stage contains steps like UAT, data migration, support environment preparation, stakeholders alignment, finalize documentation and solution deployment.
put the phases in the right context: evaluate system preparation activities before development start and management of the system by other groups after the final release
explicit milestones
Conclusions
Here we have seen, shortly, the main differences from Scrum, Lean and Disciplined Agile Delivery.
DAD is a very complex process and to find out the details there is just THE book to read in the final references.
A complete enterprise delivery process is something that requires months of work by an architecture board, but the point here is how to take the right direction as soon as possible, avoiding being hypnotized by buzz-words like Scrum or thinking that we are really agile just because we do a hour stand-up meeting every morning.
Start from removing your technical depth following firmly EP and DevOps practices. Then start formalizing your process methodology and make sure every one is walking on the same path.